fig, axes = plt.subplots(1, 3, figsize=(18, 5))
if 'health' in df.columns:
df['health'].value_counts(dropna=False).plot(kind='bar', ax=axes[0], color='#328cc1', title='Health Category Counts')
axes[0].set_xlabel('health')
axes[0].set_ylabel('count')
else:
axes[0].text(0.5, 0.5, 'health column not available', ha='center', va='center')
axes[0].set_axis_off()
income_min = None
income_max = None
income_median = None
income_p95 = None
income_p99 = None
if 'income' in df.columns:
income = df['income'].dropna()
income_min = float(income.min())
income_max = float(income.max())
income_median = float(income.median())
income_p95 = float(income.quantile(0.95))
income_p99 = float(income.quantile(0.99))
focused_income = income[income <= income_p99]
axes[1].hist(focused_income, bins=30, color='#d9b310', edgecolor='white')
axes[1].axvline(income_median, color='#0b3c5d', linestyle='--', linewidth=2, label=f'median = {income_median:.2f}')
axes[1].axvline(income_p95, color='#b45309', linestyle=':', linewidth=2, label=f'95th pct = {income_p95:.2f}')
axes[1].set_title('Income Distribution (up to 99th percentile)')
axes[1].set_xlabel('income')
axes[1].set_ylabel('count')
axes[1].legend(frameon=False)
axes[1].text(
0.98,
0.95,
f'99th pct = {income_p99:.2f}\nmax = {income_max:.2f}\n1% of rows exceed the chart range',
transform=axes[1].transAxes,
ha='right',
va='top',
fontsize=9,
bbox={'facecolor': 'white', 'edgecolor': '#cbd5e1', 'boxstyle': 'round,pad=0.3'}
)
axes[2].boxplot(
income,
vert=False,
patch_artist=True,
boxprops={'facecolor': '#fde68a', 'edgecolor': '#b45309'},
medianprops={'color': '#0b3c5d', 'linewidth': 2},
whiskerprops={'color': '#b45309'},
capprops={'color': '#b45309'},
flierprops={'marker': 'o', 'markerfacecolor': '#dc2626', 'markeredgecolor': '#dc2626', 'markersize': 3, 'alpha': 0.4}
)
axes[2].set_title('Income Spread and Outliers')
axes[2].set_xlabel('income')
axes[2].set_yticks([])
else:
axes[1].text(0.5, 0.5, 'income column not available', ha='center', va='center')
axes[1].set_axis_off()
axes[2].text(0.5, 0.5, 'income column not available', ha='center', va='center')
axes[2].set_axis_off()
plt.tight_layout()
visual_report_path = OUTPUT_DIR / 'capstone_1_visual_observations.png'
fig.savefig(visual_report_path, bbox_inches='tight')
plt.show()
most_common_health = df['health'].mode().iat[0] if 'health' in df.columns else 'not available'
mean_visits = float(df['visits'].mean()) if 'visits' in df.columns else None
print('Saved visual observations figure to:', visual_report_path)
print('Visual observations report:')
print('- The most common health category in the dataset is:', most_common_health)
if income_min is not None and income_max is not None:
print(f'- Income ranges from {income_min:.4f} to {income_max:.4f}.')
if income_median is not None and income_p99 is not None:
print(f'- The income chart is focused on values up to the 99th percentile ({income_p99:.2f}) so the main distribution is readable, while the boxplot still shows the full outlier range.')
print(f'- The median income is {income_median:.2f}, and the 95th percentile is {income_p95:.2f}.')
if mean_visits is not None:
print(f'- The average number of visits is {mean_visits:.2f}.')
print('- The dataset is concentrated in the `average` health category, while income is strongly right-skewed with a small number of extreme high-income observations.')

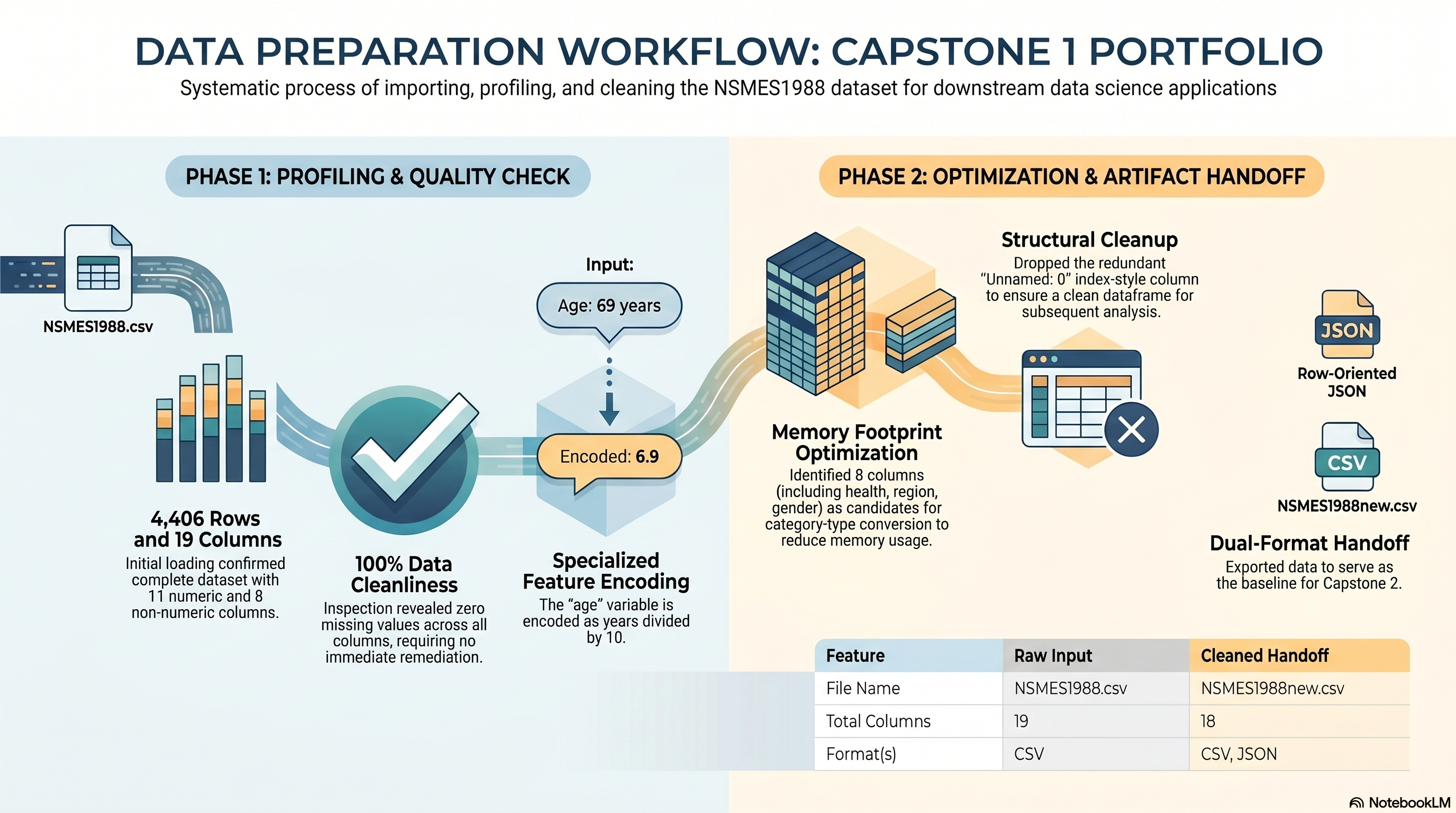






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}