evaluations_df.to_csv(OUTPUTS_DIR / 'session_10_model_comparison.csv', index=False)
summary = {
'source_counts': split_manifest['source_counts'],
'generated_counts': split_manifest['generated_counts'],
'class_indices': class_indices,
'pdf_expected_classes': PDF_EXPECTED_CLASSES,
'available_source_classes': AVAILABLE_CLASS_FOLDERS,
'missing_pdf_classes_from_source': MISSING_PDF_CLASSES,
'source_governance_notes': [
'PDF directions are the source of truth for task sequence and deliverables (Task A, Task B, Task C).',
'GitHub-backed dataset assets are the source of truth for notebook inputs per Project_DEV_Rules_PROMPT.md.',
'When PDF-expected classes are missing from source files, execution uses available classes and records the gap explicitly.',
'The generated train/test split is a fixed stratified sample to keep transfer-learning runs executable on the current CPU-only environment.',
],
'model_results': evaluations,
'best_model': evaluations_df.iloc[0].to_dict(),
'best_model_example_predictions': prediction_examples[best_model_name],
}
with open(OUTPUTS_DIR / 'session_10_summary.json', 'w', encoding='utf-8') as handle:
json.dump(summary, handle, indent=2)
summary
Output
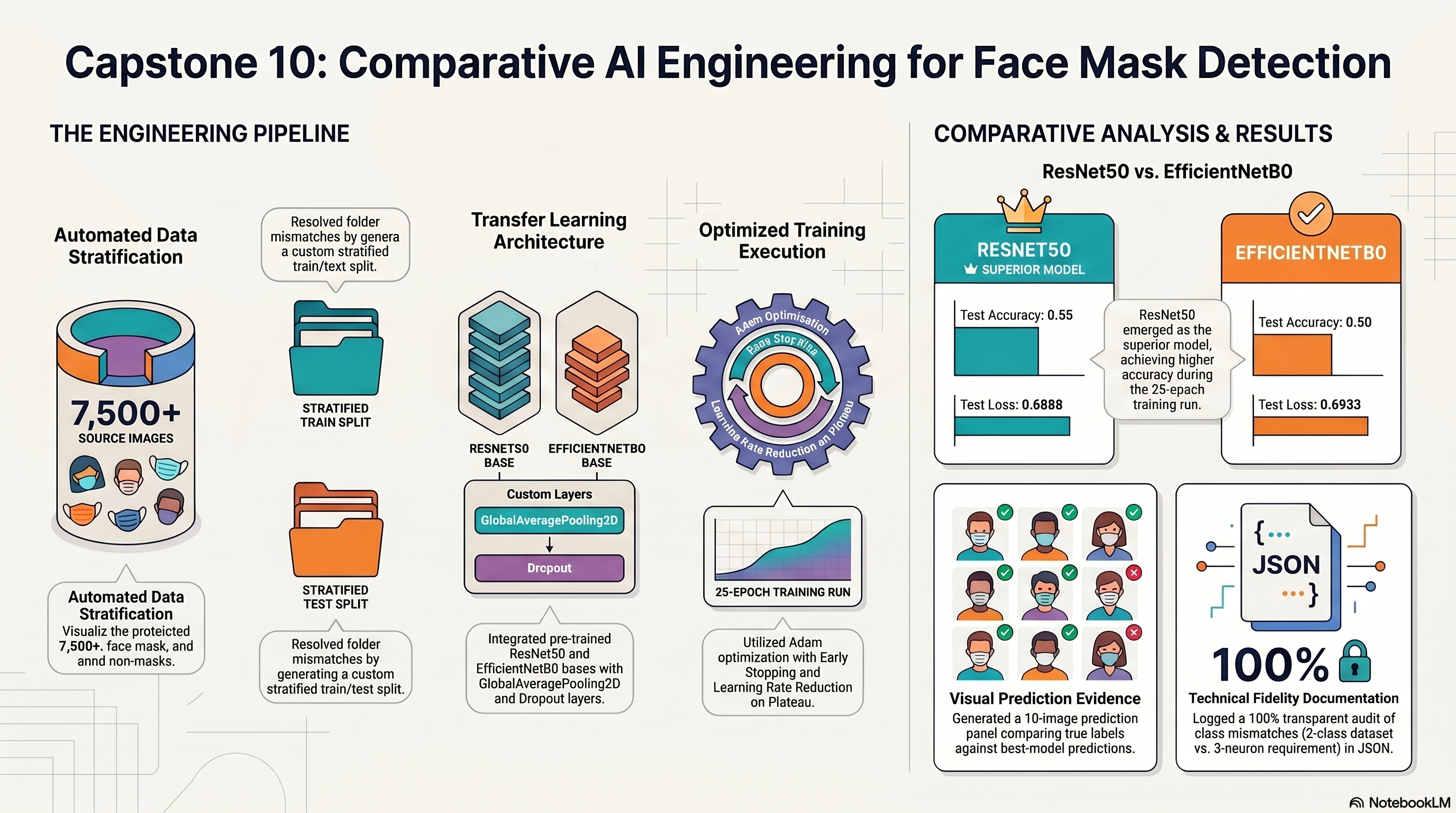
{'source_counts': {'with_mask': 3725,
'without_mask': 3828,
'mask_worn_incorrect': 1815},
'generated_counts': {'with_mask': {'train': 2980, 'test': 745},
'without_mask': {'train': 3063, 'test': 765},
'mask_worn_incorrect': {'train': 1452, 'test': 363}},
'class_indices': {'mask_worn_incorrect': 0,
'with_mask': 1,
'without_mask': 2},
'pdf_expected_classes': ['with_mask', 'without_mask', 'mask_worn_incorrect'],
'available_source_classes': ['mask_worn_incorrect',
'with_mask',
'without_mask'],
'missing_pdf_classes_from_source': [],
'source_governance_notes': ['PDF directions are the source of truth for task sequence and deliverables (Task A, Task B, Task C).',
'GitHub-backed dataset assets are the source of truth for notebook inputs per Project_DEV_Rules_PROMPT.md.',
'When PDF-expected classes are missing from source files, execution uses available classes and records the gap explicitly.',
'The generated train/test split is a fixed stratified sample to keep transfer-learning runs executable on the current CPU-only environment.'],
'model_results': [{'model': 'EfficientNetB0',
'epochs_ran': 8,
'test_loss': 0.05636788159608841,
'test_accuracy': 0.9834490418434143},
{'model': 'ResNet50',
'epochs_ran': 8,
'test_loss': 0.04874560981988907,
'test_accuracy': 0.9850507378578186}],
'best_model': {'model': 'ResNet50',
'epochs_ran': 8,
'test_loss': 0.04874560981988907,
'test_accuracy': 0.9850507378578186},
'best_model_example_predictions': {'filenames': ['mask_worn_incorrect\\1004.png',
'mask_worn_incorrect\\1007.png',
'mask_worn_incorrect\\1008.png',
'mask_worn_incorrect\\101.png',
'mask_worn_incorrect\\1010.png',
'mask_worn_incorrect\\1013.png',
'mask_worn_incorrect\\1014.png',
'mask_worn_incorrect\\1026.png',
'mask_worn_incorrect\\1027.png',
'mask_worn_incorrect\\1030.png'],
'true_labels': ['mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect'],
'predicted_labels': ['mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect',
'mask_worn_incorrect']}}






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}