A guided portfolio of capstones, live demos, and production-minded AI engineering work across data science, machine learning, and deep learning.
Capstone Project
Capstone 12
Deep learning capstone page for denoising autoencoder work, reconstruction outputs, and supporting explanations.
Capstone 12 Scope
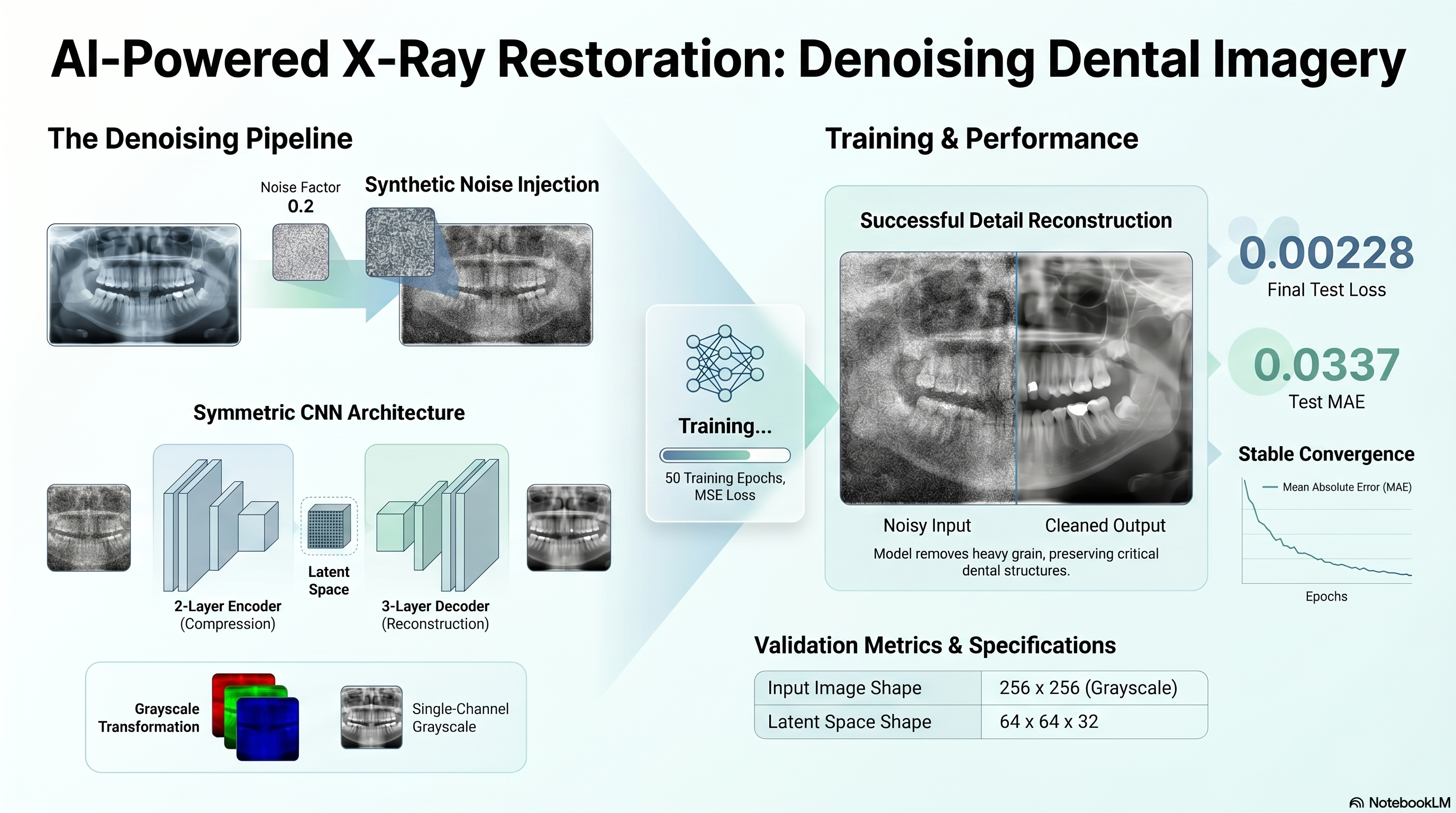
Capstone 12 converts the copied dental-autoencoder assignment into an executed denoising notebook with grayscale preparation, training-history outputs, and noisy-versus-denoised evidence panels.
The notebook records the RGB-to-grayscale handling needed to satisfy the copied decoder requirement and stages the comparison visuals under outputs/plots/.
Capstone 12 Infographic
This visual summary sits alongside the detailed walkthrough so the project can be understood quickly before drilling into the notebook, metrics, and exported artifacts.
Each walkthrough block maps the copied PDF requirements to the executed notebook cells, exported outputs, and reviewable evidence staged with this capstone.
12a
Load The NPZ Dataset And Create The Noisy Inputs
Notebook section: NPZ load and noise-generation cells
Requirement: Load the NPZ file, extract the arrays, add noise with factor 0.2, and clip the signals between 0 and 1.
The notebook loads the staged arrays, converts the RGB inputs to grayscale to satisfy the copied single-filter decoder requirement, and generates the noisy train/test inputs.
Results Capture
Original shapes: {"x_train":[92,256,256,3],"x_test":[24,256,256,3]}.
This TensorFlow Playground embed is a concept sandbox for the hidden-representation ideas behind the dental autoencoder capstone. It does not run the denoising autoencoder or use the panoramic image data; instead, it uses synthetic problems to make hidden-layer transformation, network depth, and stability under noise easier to inspect before you compare them to the real Session 12 reconstruction outputs.
What This Is
The playground is still a classifier demo, so it is not a direct autoencoder replica.
Its value on this page is conceptual: it lets you watch how hidden layers reshape inputs into more useful internal structure before the model produces an output.
That is closely related to the Session 12 encoder-decoder idea, where the network must learn a stable internal representation before reconstructing the cleaner image.
How To Use It
Pick a preset card above the playground and load it just before the iframe.
Press Play inside the playground to train that scenario and watch how the hidden layers change the learned output surface.
Use the deeper and noisy presets to connect what you see here to the encoder depth and denoising goals in the notebook.
Return to the Session 12 reconstruction plots afterward to connect the concept demo back to the actual autoencoder evidence.
What To Look For
Decision Boundary Basics: expect the clearest first look at how hidden layers reshape a simple problem.
Hidden Layers On Spiral Data: expect the strongest analogy for deeper latent representations capturing harder structure.
ReLU On XOR: expect a compact example of useful nonlinear transformation in hidden space.
Regularization Under Noise: expect the closest conceptual match to the denoising goal in the real capstone.
Preset 1
Decision Boundary Basics
Begins with a simple nonlinear classifier so you can see how hidden units reshape the feature space. Session 12 is an autoencoder rather than a classifier, but this still helps explain the core idea that hidden layers learn internal representations instead of preserving the raw input structure unchanged.
Uses a deeper network on the spiral dataset to show how multiple hidden layers can capture more complex structure. That is the closest playground analogy to the encoder-decoder stack in the dental project, where compressed hidden representations are needed before the model can reconstruct cleaner outputs.
Uses ReLU activations on XOR to show how learned nonlinear transformations create a more useful internal feature space. For the denoising autoencoder, this supports the idea that the network must transform the input into a richer hidden representation before it can recover the cleaner signal.
Adds noise and regularization so you can compare a smoother, less overfit response to messy data. That makes this preset the most directly relevant one for Session 12 because the notebook is also about learning stable structure in the presence of deliberately corrupted inputs.
Use these presets to build intuition for how a model can learn stable internal structure from noisy inputs. They are concept support only; the real Session 12 evidence still comes from the notebook, screenshots, training history, and denoising artifacts saved with the project.
Colab Notebook
This section provides the notebook preview, launch link, and project file links.
The notebook opens in Google Colab when a launch URL is configured, and the project files and outputs remain available here on the site.
This notebook is generated from the copied Capstone_Session_12.pdf directions and the staged Dental-Panaromic-Autoencoder.npz dataset.
Cell 2 Markdown
Objective
Build the required denoising autoencoder, train it on the staged dental X-ray data, and compare noisy versus reconstructed outputs.
Cell 3 Markdown
Shape Note
The staged arrays are RGB-shaped (256, 256, 3), while the copied PDF also specifies a final decoder layer with 1 filter. This notebook converts the staged RGB arrays to grayscale before training so the model can satisfy the single-channel decoder requirement without inventing a third output convention.
Cell 4 Code · python
from pathlib import Path
import json
import os
import sys
from urllib.parse import quote
from urllib.request import urlretrieve
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.keras.utils.set_random_seed(42)
IS_COLAB = 'google.colab' in sys.modules
GITHUB_REPO_OWNER = 'FrancisBurnet'
GITHUB_REPO_NAME = 'francisburnet'
GITHUB_REPO_BRANCH = 'main'
CAPSTONE_ROOT = Path('Incremental Capstones/Deep Learning Specialization/Capstone Session 12')
DATA_FILENAME = 'Dental-Panaromic-Autoencoder.npz'
def build_github_url(relative_path: Path, media: bool = False) -> str:
encoded_path = quote(relative_path.as_posix(), safe='/')
if media:
return (
f"https://media.githubusercontent.com/media/{GITHUB_REPO_OWNER}/{GITHUB_REPO_NAME}/"
f"{GITHUB_REPO_BRANCH}/{encoded_path}"
)
return (
f"https://raw.githubusercontent.com/{GITHUB_REPO_OWNER}/{GITHUB_REPO_NAME}/"
f"{GITHUB_REPO_BRANCH}/{encoded_path}"
)
def resolve_capstone_dir() -> Path | None:
current = Path.cwd().resolve()
capstone_parts = CAPSTONE_ROOT.parts
for candidate in [current, *current.parents]:
if len(candidate.parts) >= len(capstone_parts) and candidate.parts[-len(capstone_parts):] == capstone_parts:
return candidate
nested_candidate = candidate / CAPSTONE_ROOT
if nested_candidate.exists():
return nested_candidate
return None
CAPSTONE_DIR = resolve_capstone_dir()
DATA_URL = build_github_url(CAPSTONE_ROOT / DATA_FILENAME, media=True)
if CAPSTONE_DIR is not None:
OUTPUT_ROOT = CAPSTONE_DIR
OUTPUT_MODE = 'permanent capstone outputs'
OUTPUT_DISPLAY = (CAPSTONE_ROOT / 'outputs').as_posix()
else:
runtime_root = Path('/content/capstone-session-12-runtime') if IS_COLAB else Path.cwd().resolve() / 'capstone-session-12-runtime'
OUTPUT_ROOT = runtime_root
OUTPUT_MODE = 'runtime scratch outputs; export final artifacts back into the capstone outputs folder'
OUTPUT_DISPLAY = 'capstone-session-12-runtime/outputs'
RUNTIME_DATA_ROOT = Path('/content/capstone-session-12-data') if IS_COLAB else Path.cwd().resolve() / 'capstone-session-12-data'
DATA_CACHE_PATH = RUNTIME_DATA_ROOT / DATA_FILENAME
RUNTIME_DATA_ROOT.mkdir(parents=True, exist_ok=True)
if not DATA_CACHE_PATH.exists():
urlretrieve(DATA_URL, DATA_CACHE_PATH)
OUTPUTS_DIR = (OUTPUT_ROOT / 'outputs').resolve()
PLOTS_DIR = OUTPUTS_DIR / 'plots'
OUTPUTS_DIR.mkdir(parents=True, exist_ok=True)
PLOTS_DIR.mkdir(parents=True, exist_ok=True)
print('Runtime:', 'Google Colab' if IS_COLAB else 'Notebook runtime')
print('Capstone artifact path:', CAPSTONE_ROOT.as_posix())
print('Data source:', DATA_URL)
print('Data runtime file:', 'capstone-session-12-data/Dental-Panaromic-Autoencoder.npz')
print('Output mode:', OUTPUT_MODE)
print('Output target:', OUTPUT_DISPLAY)
Output
Runtime: Local / notebook runtime
Repository root: X:\SIMPLILEARN\FrancisBurnetCom
Base directory: X:\SIMPLILEARN\FrancisBurnetCom\Incremental Capstones\Deep Learning Specialization\Capstone Session 12
Data path: X:\SIMPLILEARN\FrancisBurnetCom\Incremental Capstones\Deep Learning Specialization\Capstone Session 12\Dental-Panaromic-Autoencoder.npz
WARNING:tensorflow:TensorFlow GPU support is not available on native Windows for TensorFlow >= 2.11. Even if CUDA/cuDNN are installed, GPU will not be used. Please use WSL2 or the TensorFlow-DirectML plugin.





{kind=link}
{kind=link}
{kind=link}
{kind=link}