fig, ax = plt.subplots(figsize=(10, 5))
results_df.plot(x='model', y=['accuracy', 'f1_score'], kind='bar', ax=ax)
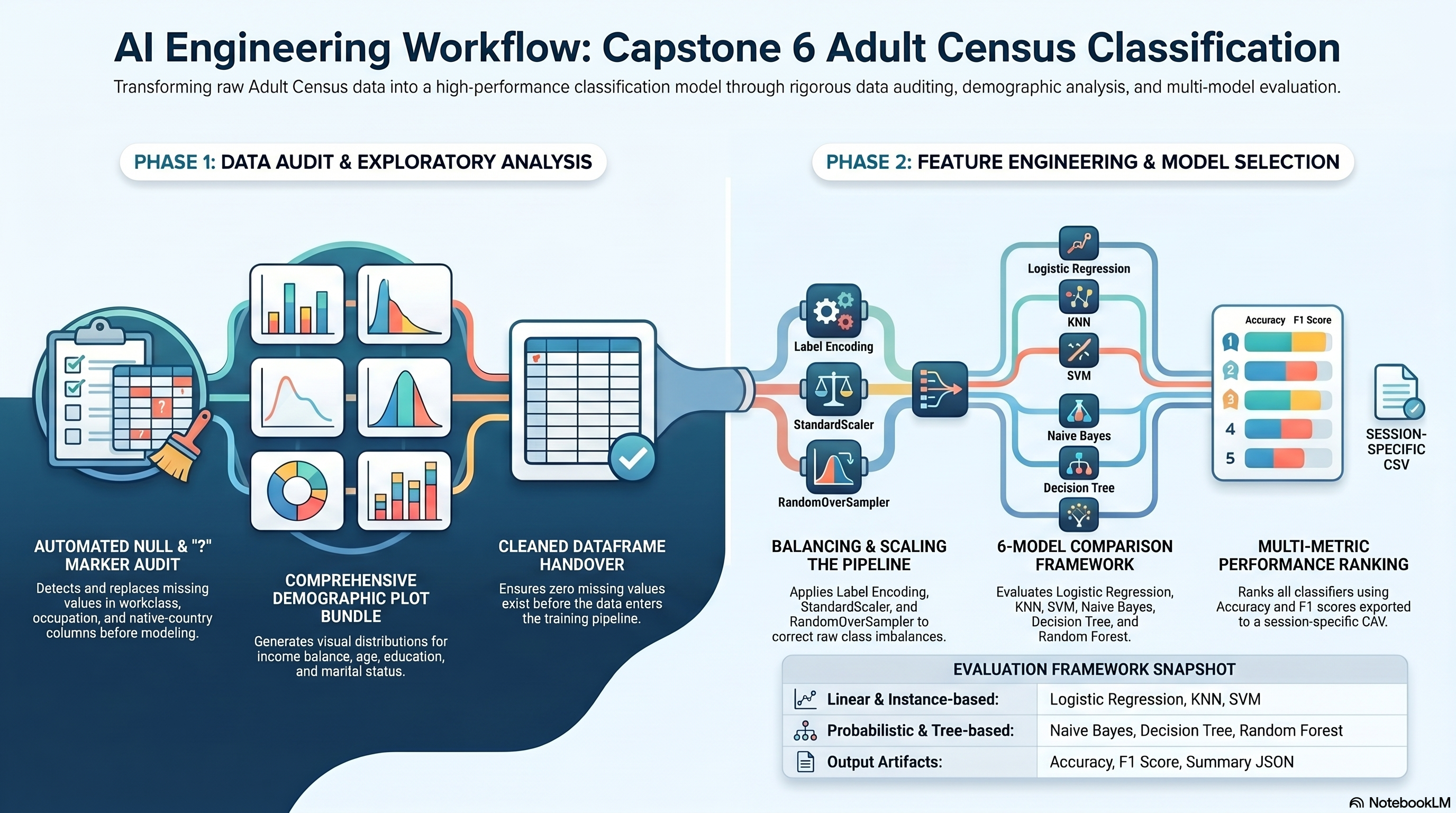
ax.set_title('Session 6 Model Comparison')
ax.set_ylim(0, 1.05)
fig.tight_layout()
fig.savefig(PLOTS_DIR / 'model_comparison.png', dpi=150)
plt.show()
plt.close(fig)
results_df.to_csv(OUTPUTS_DIR / 'session_6_model_metrics.csv', index=False)
summary = {
'dataset_shape': list(df.shape),
'question_mark_counts_before_cleaning': question_mark_counts,
'balance_summary': balance_summary,
'balanced_train_distribution': pd.Series(y_train_balanced).value_counts().to_dict(),
'correlation_to_income': correlation_to_income,
'model_results': results,
'best_model': best_model,
'notes': [
'RandomOverSampler is used as the explicit imbalance-fix technique from the PDF options.',
'The split is stratified to preserve the original class ratio before balancing the training data.',
],
}
with open(OUTPUTS_DIR / 'session_6_summary.json', 'w', encoding='utf-8') as handle:
json.dump(summary, handle, indent=2)
summary
Output
<Figure size 1000x500 with 1 Axes>
{'dataset_shape': [32561, 15],
'question_mark_counts_before_cleaning': {'workclass': 1836,
'education': 0,
'marital.status': 0,
'occupation': 1843,
'relationship': 0,
'sex': 0,
'native.country': 583,
'income': 0},
'balance_summary': {'class_counts': {'<=50K': 24720, '>50K': 7841},
'minority_ratio': 0.3172},
'balanced_train_distribution': {1: 19775, 0: 19775},
'correlation_to_income': {'income': 1.0,
'education.num': 0.335153952690943,
'age_band': 0.23638023840533365,
'age': 0.234037102648859,
'hours.per.week': 0.22968906567080932,
'capital.gain': 0.22332881819538292,
'sex': 0.21598015058403752,
'capital.loss': 0.15052631177035683,
'education': 0.07931660927729825,
'occupation': 0.03462453745149705,
'native.country': 0.02305804502812131,
'workclass': 0.0026929737847155824,
'fnlwgt': -0.009462557247529214,
'marital.status': -0.19930700917197833,
'relationship': -0.25091814171775123},
'model_results': [{'model': 'Logistic Regression',
'accuracy': 0.7759864885613389,
'f1_score': 0.6213340254347262},
{'model': 'KNN Classifier',
'accuracy': 0.7776754183939812,
'f1_score': 0.6279547790339157},
{'model': 'SVM Classifier',
'accuracy': 0.7939505604176262,
'f1_score': 0.6650024962556166},
{'model': 'Naive Bayes Classifier',
'accuracy': 0.8174420389989252,
'f1_score': 0.5677935296255907},
{'model': 'Decision Tree Classifier',
'accuracy': 0.8094580070627975,
'f1_score': 0.6000644537544312},
{'model': 'Random Forest Classifier',
'accuracy': 0.849531705819131,
'f1_score': 0.6888888888888889}],
'best_model': {'model': 'Random Forest Classifier',
'accuracy': 0.849531705819131,
'f1_score': 0.6888888888888889},
'notes': ['RandomOverSampler is used as the explicit imbalance-fix technique from the PDF options.',
'The split is stratified to preserve the original class ratio before balancing the training data.']}













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}