

Runtime Setup And Load The Updated Handoff Dataset
Notebook section: Setup and load cells
Requirement: Import Pandas, load `NSMES1988updated.csv`, and create the working dataframe.
Capstone 3 begins from the Capstone 2 handoff artifact and uses a path fallback so the notebook can resolve the updated dataset from the prior capstone output.
Results Capture
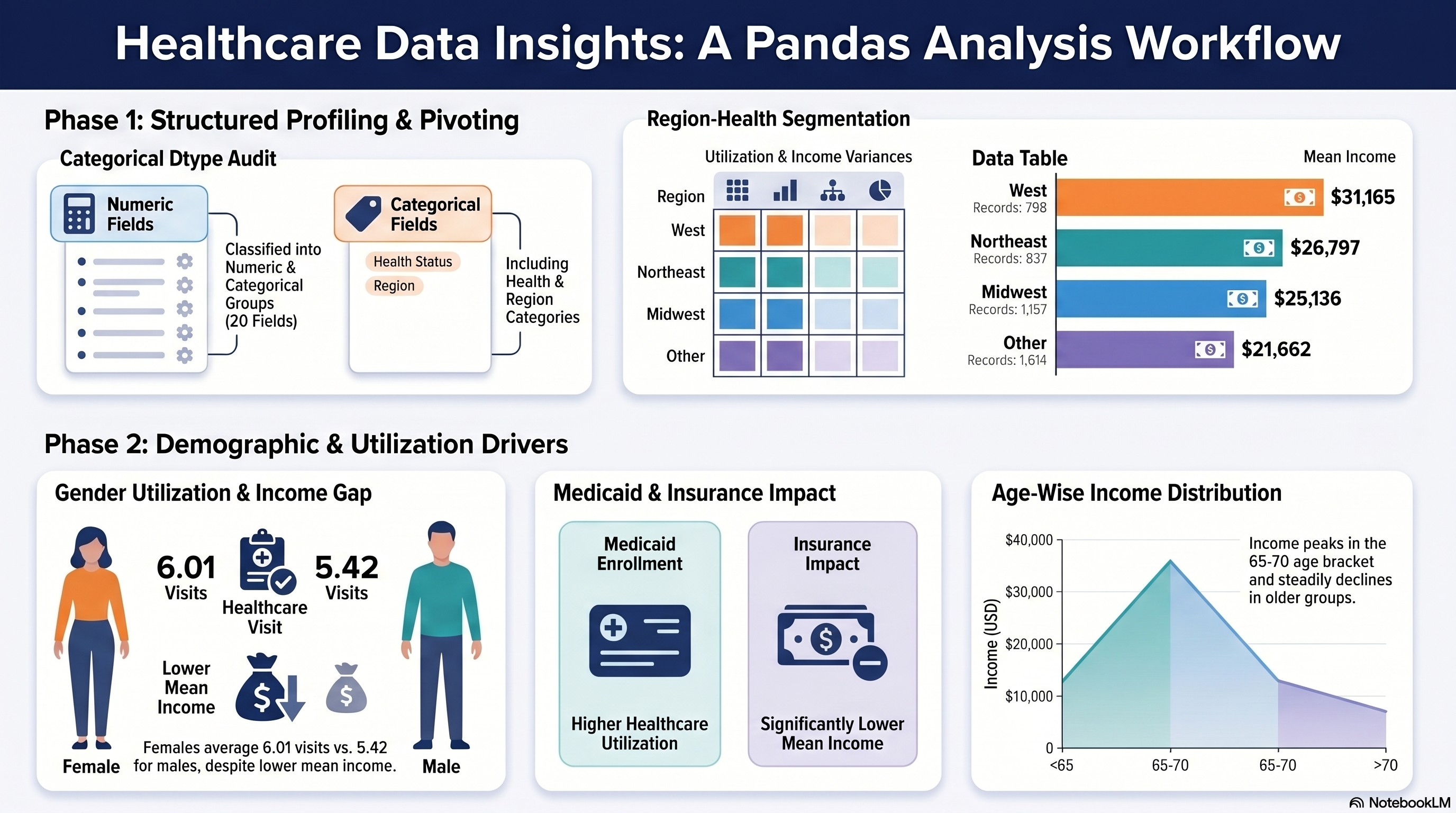
- Main input: `Capstone 2/outputs/NSMES1988updated.csv`.
- Working dataframe shape: `(4406, 20)` with the `age_years` and `income_dollars` columns already present from Capstone 2.
- Analysis starts from the updated handoff file.
import pandas as pd
DEFAULT_DATASET = "NSMES1988updated.csv"
try:
dataset_path = resolve_dataset_path(DEFAULT_DATASET)
except FileNotFoundError:
fallback = first_existing_path([
BASE_DIR.parent / "Capstone 2" / "outputs" / "NSMES1988updated.csv",
CWD / "Capstone 2" / "outputs" / "NSMES1988updated.csv",
CWD / "Incremental_Capstone" / "Capstone 2" / "outputs" / "NSMES1988updated.csv",
])
if fallback is None:
raise
dataset_path = fallback
df = pd.read_csv(dataset_path)
print("Loaded:", dataset_path)
print("Shape:", df.shape)
display(df.head())


{kind=link}
{kind=link}
{kind=link}
{kind=link}