results_df.to_csv(OUTPUTS_DIR / 'session_5_model_metrics.csv', index=False)
pd.concat(prediction_frames, ignore_index=True).to_csv(OUTPUTS_DIR / 'session_5_prediction_samples.csv', index=False)
summary = {
'dataset_shape': list(df.shape),
'train_rows': int(X_train.shape[0]),
'test_rows': int(X_test.shape[0]),
'target': target,
'categorical_columns': categorical_columns,
'numeric_columns': numeric_columns,
'model_results': results,
'best_model': best_model,
'catplot_inferences': inferences,
'notes': [
'Categorical features are encoded with pd.get_dummies() preview and pipeline one-hot encoding for model training.',
'Lasso and Ridge use sklearn default alpha values because the PDF does not specify hyperparameters.',
],
}
with open(OUTPUTS_DIR / 'session_5_summary.json', 'w', encoding='utf-8') as handle:
json.dump(summary, handle, indent=2)
summary
Output
{'dataset_shape': [8760, 18],
'train_rows': 7008,
'test_rows': 1752,
'target': 'Rented Bike Count',
'categorical_columns': ['Seasons',
'Holiday',
'Functioning Day',
'day_of_week',
'is_weekend'],
'numeric_columns': ['Hour',
'Temperature(°C)',
'Humidity(%)',
'Wind speed (m/s)',
'Visibility (10m)',
'Dew point temperature(°C)',
'Solar Radiation (MJ/m2)',
'Rainfall(mm)',
'Snowfall (cm)',
'day',
'month'],
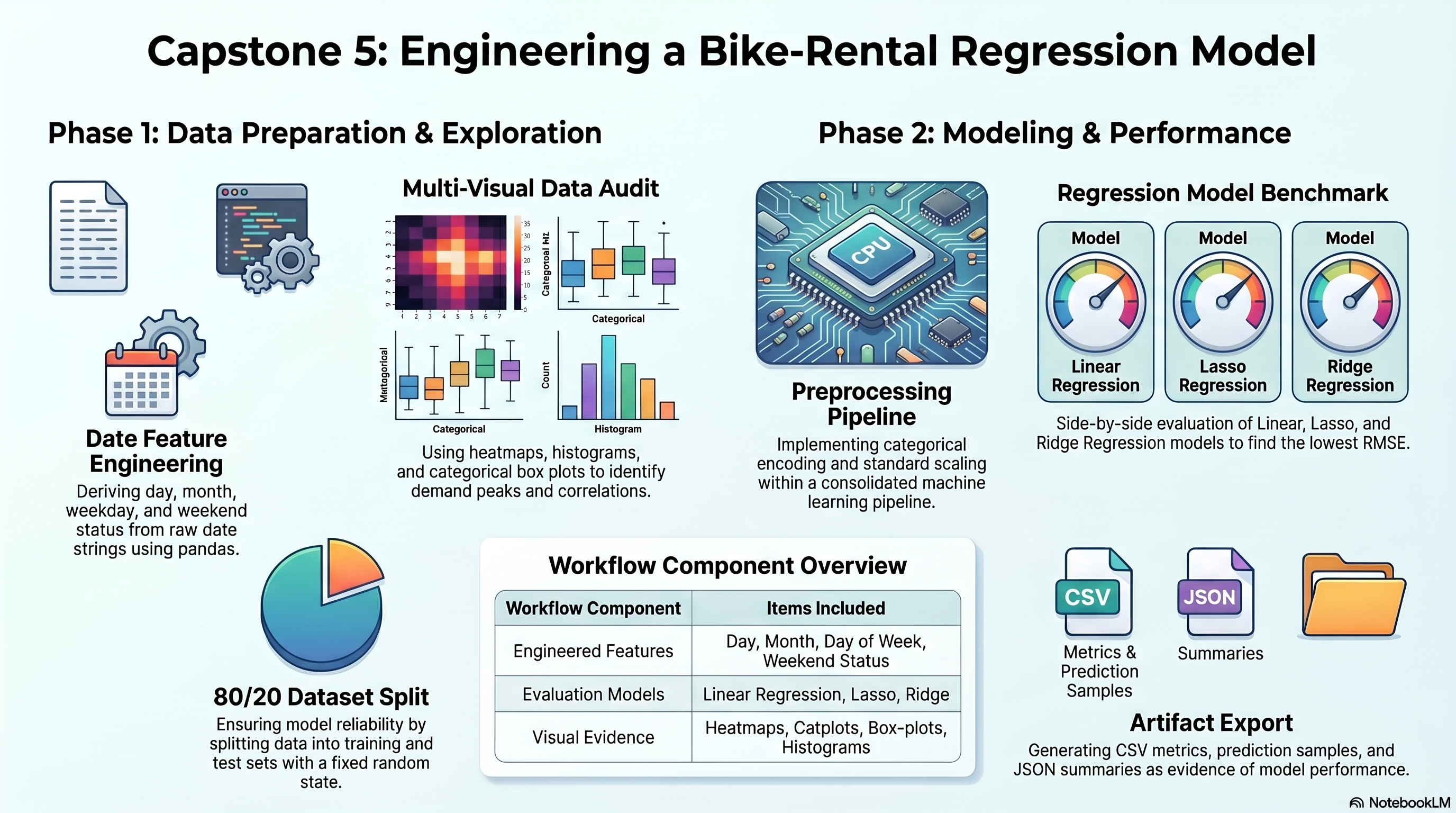
'model_results': [{'model': 'Linear Regression',
'rmse': 430.80327132329893,
'mae': 320.3593174193256,
'r2': 0.5509419599562837},
{'model': 'Lasso Regression',
'rmse': 430.29681892846634,
'mae': 319.64352934565517,
'r2': 0.5519971647497581},
{'model': 'Ridge Regression',
'rmse': 430.78827825169327,
'mae': 320.33671540137607,
'r2': 0.5509732161822174}],
'best_model': {'model': 'Lasso Regression',
'rmse': 430.29681892846634,
'mae': 319.64352934565517,
'r2': 0.5519971647497581},
'catplot_inferences': [{'feature': 'Hour',
'highest_mean_group': '18',
'highest_mean_value': 1502.926,
'lowest_mean_group': '4',
'lowest_mean_value': 132.592},
{'feature': 'Holiday',
'highest_mean_group': 'No Holiday',
'highest_mean_value': 715.228,
'lowest_mean_group': 'Holiday',
'lowest_mean_value': 499.757},
{'feature': 'Rainfall(mm)',
'highest_mean_group': '1.3',
'highest_mean_value': 764.0,
'lowest_mean_group': '7.5',
'lowest_mean_value': 9.0},
{'feature': 'Snowfall (cm)',
'highest_mean_group': '0.0',
'highest_mean_value': 732.273,
'lowest_mean_group': '7.1',
'lowest_mean_value': 24.0},
{'feature': 'day_of_week',
'highest_mean_group': 'Friday',
'highest_mean_value': 747.118,
'lowest_mean_group': 'Sunday',
'lowest_mean_value': 625.155},
{'feature': 'is_weekend',
'highest_mean_group': 'False',
'highest_mean_value': 719.449,
'lowest_mean_group': 'True',
'lowest_mean_value': 667.342}],
'notes': ['Categorical features are encoded with pd.get_dummies() preview and pipeline one-hot encoding for model training.',
'Lasso and Ridge use sklearn default alpha values because the PDF does not specify hyperparameters.']}
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}